Le Coeur de l'intelligence articielle : l'apprentissage automatique (part 1)
Publié par Olivier Serpe, le 9 février 2021 3.9k

Une voiture intelligente, un agent de dialogue (chatbot, en anglais) ou un détecteur de visages pour classer ses photos de vacances, voilà trois exemples de systèmes que l'on qualifie d'intelligence artificielle. Mais qu'est-ce que cela signifie ? « Artificielle » fait référence aux machines, quelles que soient leurs formes, qui réalisent ces tâches. Mais « intelligence » ? D'une part, il faut noter que le terme anglais intelligence possède des sens assez différents du terme français, en se traduisant notamment par renseignement. D'autre part, l'intelligence humaine est déjà un concept difficile à cerner. La définition courante de l'intelligence artificielle comme cherchant à imiter l'intelligence humaine est donc au moins aussi floue. Je vous propose donc une qualification alternative : ces trois systèmes fonctionnent grâce à un mécanisme, désormais très populaire dans le domaine de l'intelligence artificielle, nommé l'apprentissage automatique, ou Machine Learning. Et joie, les concepts impliqués sont clairement définis, car relevant principalement des mathématiques. De quoi étudier et analyser proprement.
Aujourd'hui, je vais ainsi vous présenter ce qui constitue ce mécanisme d'apprentissage automatique.
Le Problème à résoudre : entrée → fonction → sortie
Commençons par notre objectif. À chaque fois que l'on développe une IA, c'est dans le but de réaliser une tâche, de résoudre un problème ; par exemple, conduire une voiture. Pour préciser un peu, on souhaite que la voiture se conduise de façon autonome d'un point A à un point B, en toute sécurité, et en respectant le code de la route.
Pour faire cela, l'IA peut contrôler les pédales d'accélération et de frein ainsi que le volant. En d'autres termes, elle peut contrôler la vitesse et la direction du véhicule. Le rôle de l'IA va donc être d'ajuster ces deux paramètres au cours du temps afin que la voiture atteigne son objectif. Ici, on se détache des contraintes mécaniques ; ce qui nous intéresse, c'est qu'à tout moment, l'IA nous donne la vitesse à atteindre et la direction à prendre. Ces données seront la sortie du système. Elles sont produites, déterminées, par le système. Si elles sont correctes, elles permettront de réaliser l'objectif que l'on s'était fixé. Si elles sont trop erronées, l'objectif n'est pas atteint, et l'IA est défectueuse.
Bien entendu, l'IA ne peut pas inventer ex nihilo ces valeurs. La vitesse va par exemple dépendre du type de la route sur laquelle la voiture se trouve, des conditions météorologiques et des conditions de circulation. La direction va devoir suivre le tracé de la route, tout en évitant les obstacles éventuels. Pour cela, l'IA dispose de certaines informations en entrée : elle « voit » la route grâce à des caméras, elle connaît la vitesse et la direction actuelles du véhicule, sa position GPS exacte, etc.
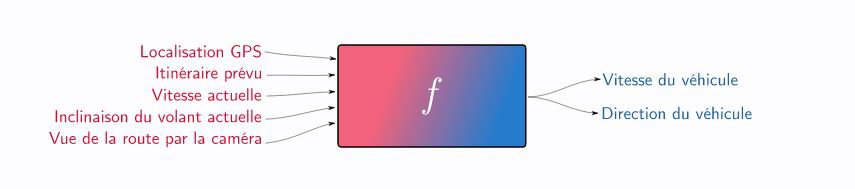

Du point de vue de l'ingénieur qui conçoit l'IA pour le système de conduite automatique de la voiture, le problème se résume à cela. On a des informations en entrée, et on veut de nouvelles informations en sortie.
Ainsi, tout le problème est de trouver le bon processus qui permette de calculer ces sorties en fonction des entrées.
En mathématiques, ce processus porte le nom de fonction, f sur le schéma ci-dessus. Cette fonction traite les entrées et renvoie des sorties. Une bonne fonction produit des sorties qui réalisent l'objectif fixé. Le mécanisme derrière cette fonction peut être très simple comme très compliqué.
Un exemple de fonction simple serait une fonction constante qui renvoie toujours la même sortie, quelles que soient les données en entrée. Par exemple, l'IA dirait toujours « Accélérer, tout droit, pied au plancher » même s'il y avait un mur en face de la voiture. Naturellement, nous ne voulons pas de ça.
Une fonction plus évoluée pourrait renvoyer en sortie la vitesse maximale prévue par le code de la route pour le type de route actuel. En ville, 50 km/h. Sur l'autoroute, 130 km/h. C'est mieux, mais toujours loin d'être suffisant pour les conditions réelles, où il faut s'adapter à chaque situation précisément.
La bonne fonction est certainement assez complexe. Après tout, même un humain passe beaucoup de temps à apprendre à conduire, et les erreurs restent malgré tout fréquentes. Et si la tâche était si simple, on pourrait d'ailleurs écrire le programme à la main. C'est là l'intérêt de l'apprentissage automatique : on laisse la machine trouver elle-même la bonne fonction à utiliser, si complexe soit-elle.
En résumé, le problème consiste à trouver, parmi toutes les fonctions possibles, une qui fournisse les bonnes données en sortie afin d'atteindre notre objectif.
Dans la suite de cet article, on se concentrera sur une fonction avec une seule sortie : la vitesse que doit atteindre la voiture autonome. Cela simplifie la compréhension, et la gestion de l'inclinaison du volant fonctionnerait de la même façon.
Vers une description quantitative de l'apprentissage
Nous l'avons dit, le problème à résoudre est la recherche de la fonction idéale. « Mais comment faire ? » me demanderez-vous. Premièrement, nous avons besoin d'un moyen pour estimer quantitativement si une fonction remplit bien notre objectif ou non.
Pour ce faire, les chercheurs ne sont pas allé chercher bien loin. On fait passer à l'IA un contrôle, comme à l'école. On lui donne des informations en entrée (pour filer la métaphore, des questions) pour lesquelles les sorties (les réponses) sont connues et attendues, i.e. généralement calculées à la main ou mesurées expérimentalement. On compare les sorties produites par l'IA à celles attendues (on corrige la copie) et on donne un nombre (une note) qui quantifie la réussite de l'IA.
Reconnaître son erreur
Prenons l'exemple de notre IA pour une voiture autonome, dans la situation suivante :
On demande à un humain quelle serait la vitesse à adopter. Disons, dans un premier temps, 30 km/h. Il s'agit donc de la sortie attendue. Maintenant, cette situation est donnée comme entrée aux fonctions à évaluer. Voici leurs réponses :
- Fonction n°1 : 150 km/h
- Fonction n°2 : 12 km/h
- Fonction n°3 : 33 km/h
C'est la fonction 3 qui semble mieux performer. La fonction 1 accélère beaucoup trop et la fonction 2 ralentit trop. La fonction 3 n'est pas parfaite mais s'approche de ce que l'on souhaite. On peut d'ailleurs être plus précis dans notre analyse, en calculant l'erreur de prédiction de chacune de ces fonctions :
- La fonction n°1 s'est trompée de 120 km/h.
- La fonction n°2 s'est trompée de 18 km/h.
- La fonction n°3 s'est trompée de 3 km/h.
On peut désormais précisément quantifier la performance de chacune des fonctions. La fonction n°3 a produit 10% d'erreur. La fonction n°2 est six fois pire, la fonction n°1 est quarante fois pire.
Objectif zéro gaffe
Bien sûr, une seule évaluation est loin d'être suffisante. La fonction 3 a peut-être donné le meilleur résultat dans cette situation, mais qui dit qu'elle le fera dans toutes les autres situations ? Si par exemple, elle donnait ses résultats au hasard, et bien, coup de chance, ça marche dans ce cas-ci, mais elle donnerait des résultats totalement faux pour toutes les autres situations. Pour s'extraire de ce genre de problèmes, on évalue toujours les fonctions sur des quantités importantes de données. Dans le cas de la voiture, on va lui donner plusieurs millions de situations que l'on connaît déjà pour s'assurer qu'elle réponde correctement à toutes les situations.
Dans le processus d'apprentissage, on note, pour chaque situation d'entraînement, l'erreur commise. On obtient alors une liste de toutes les erreurs commises, dont on peut calculer la moyenne. Par exemple, dans le cas de la voiture, pour environ un million de situations testées :
- en moyenne, la fonction 1 se trompe de 70 km/h,
- en moyenne, la fonction 2 se trompe de 13 km/h,
- en moyenne, la fonction 3 se trompe de 5 km/h.
Voilà qui est rassurant, la fonction 3 a l'air vraiment meilleure que ses comparses.
Meilleure est la fonction, plus elle remplit son objectif, plus basse sera son erreur. Cette erreur permet de classer toutes les fonctions entre elles. Idéalement, on cherche donc une fonction avec une erreur moyenne de 0 km/h, mais tomber si parfaitement sur 0 peut ne pas être possible en pratique, donc on cherchera surtout à trouver la fonction avec le minimum d'erreur moyenne. Notez que l'un n'empêche pas l'autre.
À la Recherche de la fonction optimale
Regardez comment le problème change petit à petit de forme. Nous avons commencé par chercher une voiture autonome. Maintenant, nous nous intéressons à trouver une fonction qui nous produise la plus petite erreur moyenne sur un jeu de données.
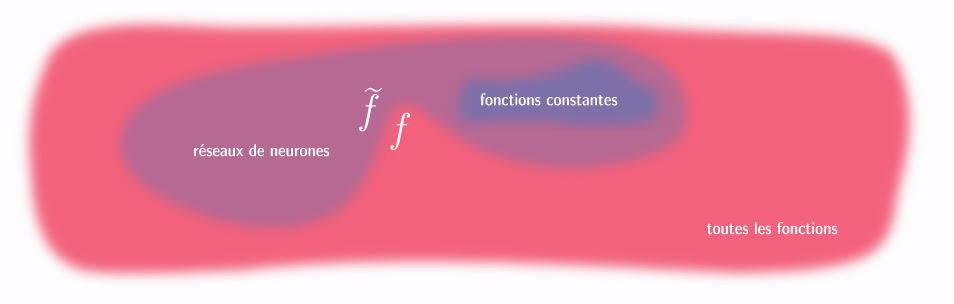
Ainsi, on peut se dire qu'il existe une méthode parfaite pour trouver la fonction idéale : on regarde chacune des fonctions possibles, on calcule son erreur moyenne, et on garde celle avec la plus petite. Pour les matheux, cela s'appelle de l'optimisation, et c'est le socle théorique sur lequel s'appuie l'apprentissage automatique. En théorie, cela marche parfaitement. Le problème, c'est qu'en pratique, tester toutes les fonctions serait beaucoup trop long, et même impossible : il y en a une infinité !
Par exemple, il y a la fonction qui donne toujours une vitesse de 1 km/h. Celle qui donne toujours une vitesse de 2 km/h, celle qui donne toujours 3 km/h, etc. Vous voyez comment cela continue. Nous avons déjà une infinité de fonctions possibles, alors que nous ne comptons que les fonctions constantes à valeurs entières ! Il va donc falloir ruser.
Limitation du nombre de fonctions candidates
Nous cherchons une épingle dans une botte de foin. Pour nous aider, nous commençons donc par prendre une botte de foin plus petite, en se restreignant à un certain type de fonctions.
On pourrait par exemple choisir de ne considérer que les fonctions qui renvoient une vitesse constante et entière (1 km/h, 2 km/h, 3 km/h, 4 km/h, etc.). Bon, il y en a toujours une infinité, mais nous pouvons alors introduire une nouvelle contrainte : cette vitesse constante ne doit pas dépasser 130 km/h. Ça nous laisse donc 131 possibilités, il est donc facile pour un ordinateur d'en faire le tour.
Malheureusement, nous avons trop simplifié notre problème, car il est certain que rouler toujours à la même vitesse n'est pas souhaitable. Se limiter aux fonctions à vitesse constante était une limitation trop forte. Il faut donc trouver un bon équilibre : garder assez de complexité pour être certain qu'une fonction idéale existe, tout en gardant assez de simplicité pour qu'un ordinateur ait le temps d'explorer les possibles avant que l'Univers disparaisse.
Pour cela, il existe un type de fonctions très populaire dont vous avez sûrement déjà entendu parler : les réseaux de neurones. Nous n'expliquerons pas ici ce qui fait leur spécificité, mais sachez que s'ils sont utilisés comme ils le sont, c'est pour cette formidable capacité à allier une forme simple avec une expressivité très complexe.
La meilleure fonction pour notre problème de voiture n'est sûrement pas une de ces fonctions, mais il est très (très) probable qu'au moins une d'entre elles en soit une très bonne approximation.

Les Pouvoirs magiques des mathématiques
La dernière brique de notre édifice, et certainement la plus importante. Nous avons dit plus haut que le problème que l'on cherchait à résoudre tenait de la branche des mathématiques nommée l'optimisation. Et fort heureusement, beaucoup de mathématiciens ont travaillé sur ces problèmes. Et ils ont notamment développé des méthodes pour affiner très précisément l'exploration des fonctions possibles.
Dans le cas des réseaux de neurones par exemple, il existe par exemple un algorithme dit de la descente du gradient. C'est certainement l'un des plus utilisé à l'heure actuelle, lui et ses innombrables variantes. Pour fonctionner, on commence avec une fonction quelconque, qui est probablement assez mauvaise pour atteindre l'objectif fixé. À l'aide des données dont on dispose, on calcule l'erreur produite par cette fonction. Et là, un mécanisme nommé la rétropropagation du gradient permet de déterminer comment modifier l'intérieur de la fonction pour qu'elle s'améliore. De notre fonction médiocre, on arrive alors à une fonction un peu moins médiocre. Et petit à petit, notre erreur diminue. Avec assez de temps et de données, nous pouvons même espérer trouver notre fonction idéale ou son approximation.
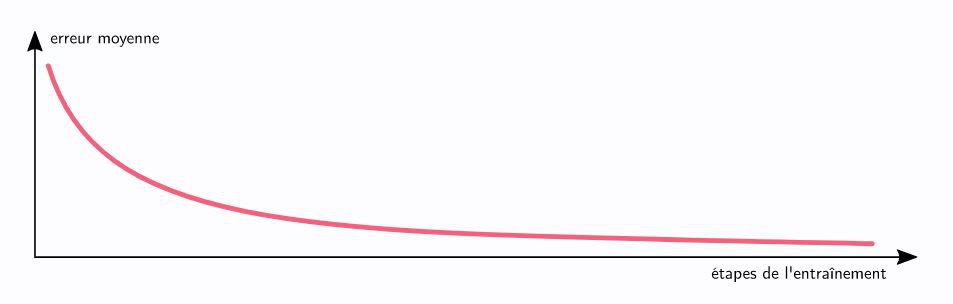

Il est difficile d'être bref dans la présentation d'un tel algorithme. L'important est l'existence de telles méthodes, mises au point par des mathématiciens, pour explorer efficacement le champ des possibles. Ces méthodes fonctionnent en théorie, ça les mathématiciens l'ont démontré. Mais elles fonctionnent également en pratique, au vu des récents succès atteint dans les nombreux domaines de l'intelligence artificielle.
Cette étape d'exploration des fonctions candidates et de sélection de la meilleure fonction est souvent nommée entraînement.
Les Raisons du succès
Pourquoi ça marche ? Ce qui a été décrit jusqu'ici concerne le comment, les outils utilisés et la façon de les utiliser. Ces outils sont appelés des algorithmes. Un algorithme est une suite d'opérations, d'instructions basiques, qu'un ordinateur exécute les unes à la suite des autres. C'est donc un système très primaire. Il est ainsi légitime de se demander par quel miracle des objets (en apparence) si simples parviennent à « comprendre » des mécanismes si compliqués, comme la conduite d'une voiture.
Information et statistique
La réponse est assez fondamentale à propos de la conception du monde, aussi réduite puisse-t-elle être, que possède une intelligence artificielle. Pour une IA, tout n'est qu'information. En informatique, ces informations sont des nombres. L'IA a donc seulement accès à une liste de nombres. Pour reprendre la terminologie utilisée précédemment dans cet article, ces nombres sont les « entrées » de l'IA.
Ces nombres ne sont pas strictement aléatoires : ils ne sont pas tirés au sort ni laissés au hasard. Non, ils représentent la réalité.
Considérons par exemple un capteur de bruit (de volume sonore) produisant le relevé suivant :
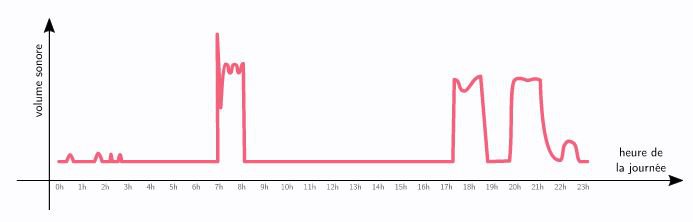
On peut facilement représenter cette information comme une liste de nombres, par exemple en exprimant le volume en décibels toutes les dix minutes. Si ces nombres étaient aléatoires, on verrait un gribouillage sans intérêt. Mais ils ne le sont clairement pas ; mieux même, ils laissent transparaître bien d'autres informations :
- Presque aucun bruit entre 23h et 7h du matin, aucun bruit entre 8h et 17h30 : on se situe dans une chambre, où quelqu'un dort la nuit et travaille le jour. D'ailleurs, le premier pic à 7h du matin est probablement un réveil.
- La personne mange sur son lieu de travail car il n'y a aucun pic au milieu de la journée.
- La personne vit dans une maison ou un grand appartement, car il n'y a aucun bruit entre 19h et 20h, heure du dîner, qui se passe dans une autre pièce.
- La personne ronfle un peu, car on voit des petits pics pendant la nuit.
- Enfin, étant donné toutes ces informations, on peut suspecter que la personne en question est un enfant. Les horaires correspondent aux horaires d'un jour d'école. La personne semble dans sa chambre avant le repas et ne prépare donc pas le repas. Et enfin, on pourrait penser qu'elle fait semblant d'aller se coucher vers 22h mais discrètement joue encore pendant une petite heure...
Certes, beaucoup d'éléments sont incertains et sûrement extrapolés. Mais enfin, nous avons tout de même pu tirer beaucoup d'informations à partir d'un simple relevé de volume sonore, ie. à partir d'une simple liste de nombres.
Ces nombres, parce que qu'ils ne sont pas complètement choisis au hasard, contiennent en eux des informations qu'une analyse statistique peut permettre de révéler.
Apprentissage et généralisation
Lorsqu'on entraîne une IA, on lui donne énormément de données en entrée. Elle va alors effectuer des analyses statistiques poussées sur ces données. C'est le rôle des méthodes mathématiques citées plus haut. Durant ces analyses, l'IA va extraire, de ces données, les informations et les relations qui lui sont utiles pour résoudre la tâche qui lui a été confiée. En ce sens, elle apprend.
Par exemple, toujours pour notre voiture, à force de voir la condition météorologique « pluie » revenir dans les situations où les essuie-glaces sont activés, la prochaine fois qu'il pleuvra, elle comprendra qu'il faut activer les essuie-glaces. À force de voir que les phares sont allumés lorsqu'il fait nuit, lorsqu'il pleut fort ou lorsque l'on se trouve dans un parking ou un tunnel, elle comprendra qu'il faut allumer les phares lorsque la visibilité est réduite. Et ainsi de suite.
Enfin, il y a un écueil très récurrent dans ces approches. Du fait que toutes ces « règles » soient apprises par l'IA à partir des données qu'on lui fournit, on peut se retrouver dans des cas bizarres où l'IA sait parfaitement réagir dans les situations qu'elle a déjà vu mais agit très mal dès qu'une situation nouvelle se présente.
Pour faire une analogie, c'est comme si on donnait un livre à des étudiants. Certains l'apprennent par cœur et les autres cherchent à en comprendre la logique et en étudient le sujet plus globalement. Vient l'heure du premier contrôle, qui porte très exactement sur le contenu du livre. Ceux qui l'ont appris par cœur réussissent très bien, avec une moyenne de 19/20. Les autres sont un peu moins bons mais ils ont compris assez d'éléments pour obtenir une moyenne de 15/20. Vient maintenant le second contrôle, qui porte sur le même thème, mais sur un contenu précis différent de celui du livre. Ceux qui avaient appris par cœur sans comprendre performent alors très mal, et obtiennent une moyenne de 4/20. Les autres se maintiennent à leur niveau et obtiennent 15/20.
Ce problème porte le nom d'overfitting, en anglais, que l'on pourrait traduire par sur-apprentissage ou sur-ajustement. Malheureusement, mal calibrées, beaucoup des méthodes d'analyse statistiques vont se faire avoir et surinterpréter les données. Une bonne IA est donc celle qui est capable, à partir de ces données, de déduire de bonnes règles pour le cas général. C'est ce qu'on appelle la généralisation, le cœur de l'apprentissage automatique, le cœur de nombreux systèmes actuels d'intelligence artificielle.


Conclusion
Cet article vous a présenté le principe d'apprentissage supervisé, l'une des branches de l'apprentissage automatique. On nourrit une IA avec des données pour lesquelles on sait ce qu'elle doit répondre. Grâce à une analyse statistique de ces données, l'IA comprend quelles sont les critères qu'elle doit retenir pour répondre, dans le cas général, aux questions qui lui sont posés.
Pour aller plus loin
Quelques documents à venir emprunter à la médiathèque :
- 📕 (tour d'horizon des réalisation majeures en intelligence artificielle) 3 minutes pour comprendre 50 avancées majeures de l'intelligence artificielle / Luis de Miranda ; Steve Rawlings ; traduit de l'anglais par Véronique Dumont ; Collectif.- PARIS. ; Courrier du Livre (Le) , 2019.- 160 p. : illustrations en couleur ; 23 cm.- (3 minutes pour comprendre).
- 📕 (approche didactique aux nombreux champs couverts par l'intelligence artificielle) Comprendre l'intelligence artificielle / Nicolas Sabouret ; Lizete De Assis.- Paris : Ellipses Marketing , 2019. ; Ellipses Marketing , 2019.- 208 p. : illustrations en noir et blanc ; 21 cm.
- 📕 (très complet et très concret) L'intelligence artificielle pour les nuls / John Paul Mueller, Luca Massaron.- Paris : First interactive , 2019.- 341 p. : illustrations en noir et blanc ; 23 cm.- (Pour les nuls : avec les nuls, tout devient facile !).
Quelques vidéos françaises de vulgarisation :
- 🎬 Le deep learning, par ScienceEtonnante, qui introduit les spécificités des réseaux de neurones.
- 🎬 L'intelligence artificielle et le machine learning, une série de 54 vidéos par Science4All dont des présentations précises des réseaux de neurones, de la descente du gradient et de la rétropropagation.
- 🎬 L'intelligence des machines - Introduction au MACHINE LEARNING (apprentissage automatisé) par Defend Intelligence, pour une description pratique, du point de vue d'un ingénieur, de l'apprentissage automatique.
Pour les anglophones ou ceux qui n'ont rien contre les sous-titres (en français) :
- 🎬 Neural networks, une série de 4 vidéos par 3Blue1Brown présentant les aspects mathématiques concrets des réseaux de neurones, de l'algorithme de descente du gradient et de la rétropropagation du gradient, avec de très belles animations !


